2021-0107-Finding Bugs Using Your Own Code: Detecting Functionally-similar yet Inconsistent Code
作者:Mansour Ahmadi, Reza Mirzazade Farkhani, Ryan Williams, Long Lu
单位:Northeastern University
会议:USENIX SECURITY 2021
论文链接:Finding Bugs Using Your Own Code: Detecting Functionally-similar yet Inconsistent Code
Abstract
通过机器学习的概率分类的方式能够成果检测出软件中的已知类型错误,但是需要大量的代码样本用于训练模型。作者提出了一种基于机器学习、不需要额外代码样本进行训练的bug检测方式。核心思想是通过发现同一功能代码在不同函数中的实现的不一致性,从而发现bug。与先前工作差异主要在:不需要额外的训练集、不需要指定bug类型、可以发现未知类型的bug。作者在包括QEMU、OpenSSL等5款开源软件上进行测试,发现了22个新的bug。
Introduction
通过机器学习的方式检测软件bug被广泛研究且取得了不少的成果,然而现有的基于机器学习的错误检测技术的high-level idea基本相似:通过大量已知bug训练模型以发现类似的bug。这样的方式存在两个方面的局限性:1. 需要大量的已知漏洞样本,2. 仅对于特定类型漏洞的具有检测效果(bug-specific),对于不同类型的漏洞检测效果不同,且对于未知类型漏洞的检测效果较差。
在部分较大规模的项目中,功能相似的代码片段通常由不同的开发者提交,个别开发者提交的有问题代码很可能与其他non-buggy的代码片段存在差异。因此,作者提出了一种基于机器学习、除带分析的codebase之外不需要额外代码样本的漏洞检测方式,命名为FICS(Functionally-similar yet Inconsistent Code Snippets)。其通过在codebase中发现相似功能代码的不一致实现定位可能有问题的代码。
Figure 1: high-level workflow
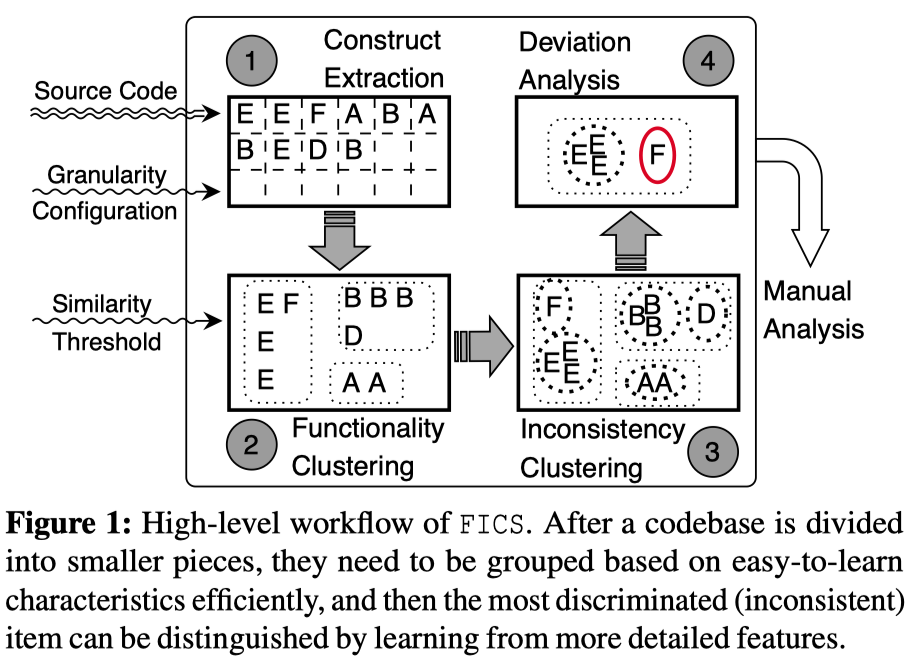
FICS主要解决的两个问题:1. 找到一种合适的粒度,使之能够发现功能类似且具有不一致性的代码片段。 2. 使FICS可以扩展并应用到较大的codebase中。
作者提出了一种名为Construct的过程内粒度,Construct是一个可配置大小的、过程内的数据依赖图子图,这种粒度既可以发现相似性与不一致性,又可以扩展至大型项目。作者还使用到了两种graph embedding技术:bag-to-nodes(coarse-grained)、graph2vec(fine-grained)。作者使用这两项技术对Construct的相似性和不一致性进行较为精确的比较。
作者的主要贡献在于:
- 设计了FICS,第一个基于不一致性的、bug-generic的bug检测方式。
- 使用FICS扫描了五个开源项目,包括QEMU、OpenSSL,发现了22个新的bug,并发现了95个疑似多余的检查。
- 由于目前缺乏针对于不一致性检测工具的benchmark,作者提出了一个包含22个漏洞的benchmark,命名为iBench。
Background——不一致性

Related Work
ML for Bug Discovery
有监督学习:常被用于对buggy和non-buggy的代码建模,例如使用含漏洞的代码片段训练LSTM。缺点在于需要大量的精力收集、标记大量样本。
无监督学习:对已知漏洞的代码片段进行聚类,然后在每个cluster内搜索可能的漏洞变种。
Inconsistency Detection
基于AST来检测代码中的不一致性(AST中不包含语义信息)。
APIsan 通过符号执行和语义交叉检查来推断API是否正确使用。
CRIX(Detecting Missing-Check Bugs via Semantic- and Context-Aware Criticalness and Constraints Inferences)
- 只检测miss check bugs
- majority voting-based approach 不能检测 one-to-one inconsistencies
Different is Good: Detecting the Use of Uninitialized Variables through Differential Replay
FICS与先前工作的主要区别在于:1. 不仅仅针对一种或几种指定的漏洞; 2.不需要为各种漏洞手动的设置启发式规则。
Design
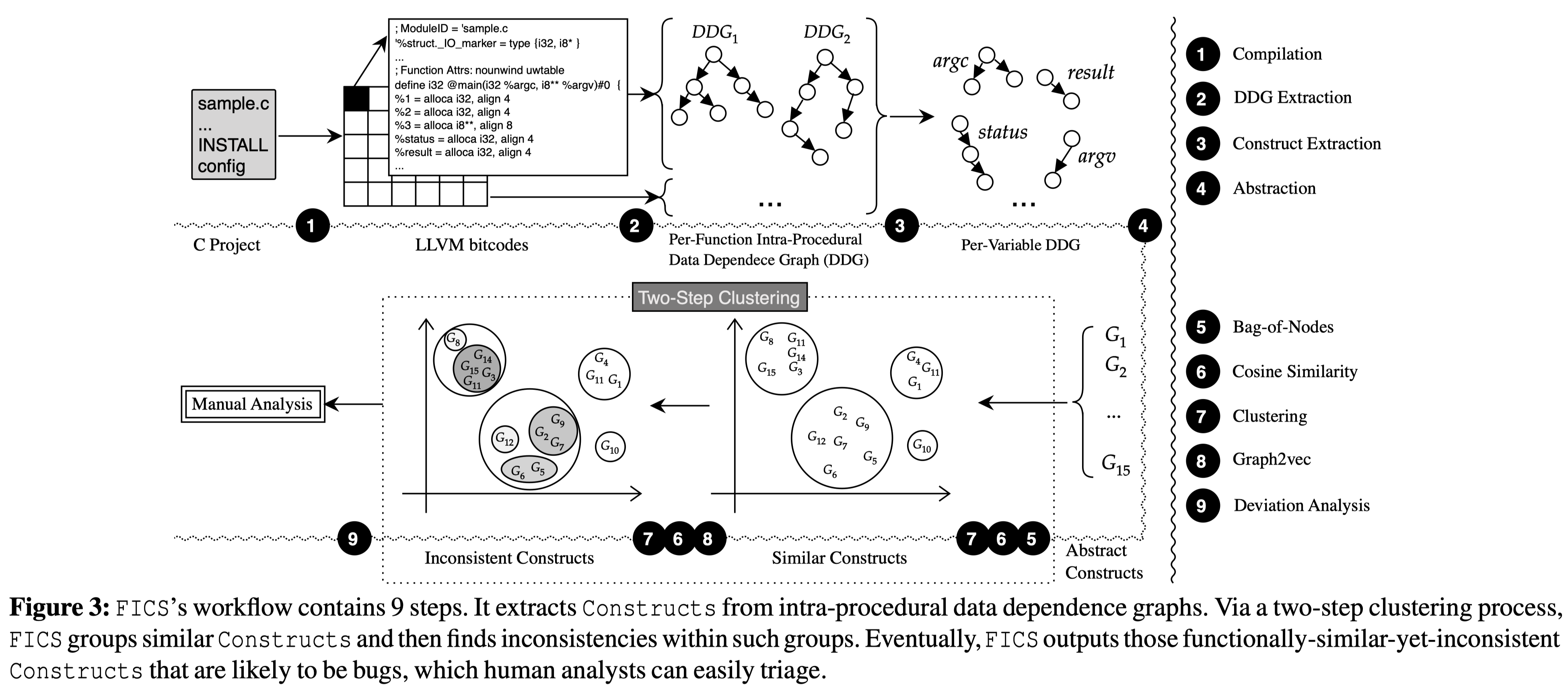
- 将给定的codebase转为LLVM bitcode
2-3. 提取出Constructs
- 对Constructs进行抽象转成通用形式
5-8. two-step 聚类
- 人工分析
Code Representation and Granularity
- Code representations
- Program Dependence Graph (PDG),说明了数据和控制流的依赖关系,语义更丰富,子图能够捕获局部的控制流、数据依赖性。
- 👉 Data dependency edge
- Control dependency edge
- Control Flow Graph (CFG),可能的执行路径及条件
- Abstract Syntax Tree (AST),包含语法信息
- Program Dependence Graph (PDG),说明了数据和控制流的依赖关系,语义更丰富,子图能够捕获局部的控制流、数据依赖性。
作者选择DDG作为Code Representation,因为:
- 单纯使用DDG即可以捕获大部分的漏洞root cause。例如,miss check、misuse API、bad casting等bug。而通过省略控制流依赖关系,可以简化代码表示,使之具备可扩展性且不会丢失常见漏洞相关的语义信息。
- 漏洞及patches通常出现于同一个函数内,所以在intra-procedural DDG可以表示大部分buggy和non-buggy的代码片段。将分析限制在单一函数内,使得FICS更具可扩展性,得以分析较大的codebase。
- 由于DDG是基于图的代码表示,其适合使用machine learning技术(embedding、clustering)进行相似性和不一致性分析。
FICS的有效性很大程度上取决于进行相似性和不一致分析的代码粒度。作者提出了一种名为Construct的过程内粒度,Construct是一个可配置大小的、过程内的数据依赖图子图。
对于一个给定的DDG,从一个特定的根结点开始遍历,遍历过(深度不超过max-depth)的边和节点组成Construct。每一个变量V与其所在的函数F决定一个Construct C。换句话说,C包含V在F中的定义及propagate的statements。
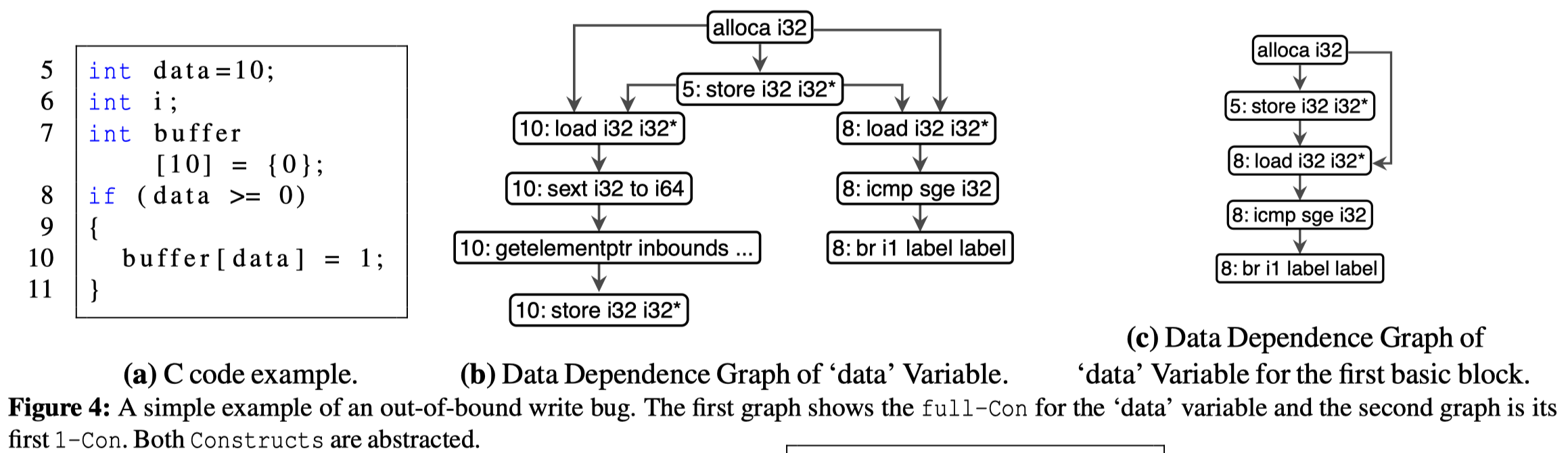
通过定义Construct,作者将“检测代码不一致性”的问题,转换为“对单一变量发现相似/不一致的操作/计算”的问题。这样就使得可以通过通用的方式和较小的代码粒度检测不一致性。
FICS对程序中每个函数的每个参数和变量以及全局变量提取Construct。随后FICS对Construct进行抽象( 4️⃣ in Figure 3),目的是:1. 移除掉可能会影响聚类的语法信息(常量及变量名);2. 进一步最小化Construct,以便于提高聚类的效率。
Two-step Clustering
作者设计了一个两步聚类的过程,首先第一次聚类将相似的Construct分组,然后在每个组中再一次聚类以识别不一致的Construct。
使用“双重镜头”类比可以很容易地解释这个高层次的想法:我们使用第一个镜头,其分辨率不是很高,但视野很广,可以检查Construct并确定那些(大致)相似的Construct。然后,我们使用分辨率更高但视野更窄的第二个镜头放大到相似Construct的每个组,并发现成员之间的差异(或不一致)。显然,第一步聚类应该稍微粗粒度并且高效,而第二步聚类应该细粒度并且能够准确地检测出细微但关键的不一致性。
Example
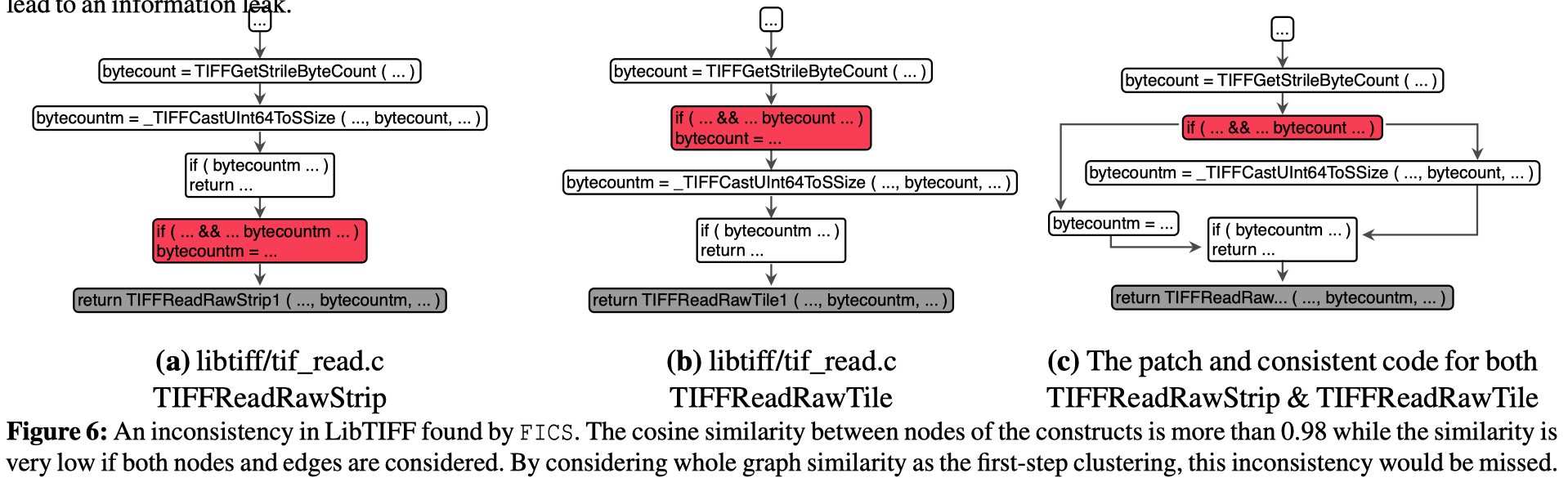
第一步聚类——Functionality Clustering(粗粒度)
如果使用标准的图相似性算法比较Figure 6(a)和(b),将会得到较低的相似度,因为其考虑了两个图中的node和edge的关系。
因此作者借鉴NLP中bag-of-words的方式,命名为bag-of-nodes。不考虑nodes之间edge的关系,即忽视节点之间的顺序关系,仅计算Construct之间nodes集合中的余弦相似度。

第二步聚类——Inconsistency Clustering(细粒度)
图同构可以实现细粒度的图匹配,然而图同构问题是一个NP-complete问题,其开销会随着图的大小急剧上升。因此在现实中常使用效率更高的graph kernels和graph embedding技术。
作者这里使用到了graph embedding中的graph2vec技术,计算出每对Construct之间的相似度,将得到的分数进行聚类。在这一步中,作者为了使得能够感知细微的差异,设置了较高的相似度阈值。
Deviation Analysis and Filtering
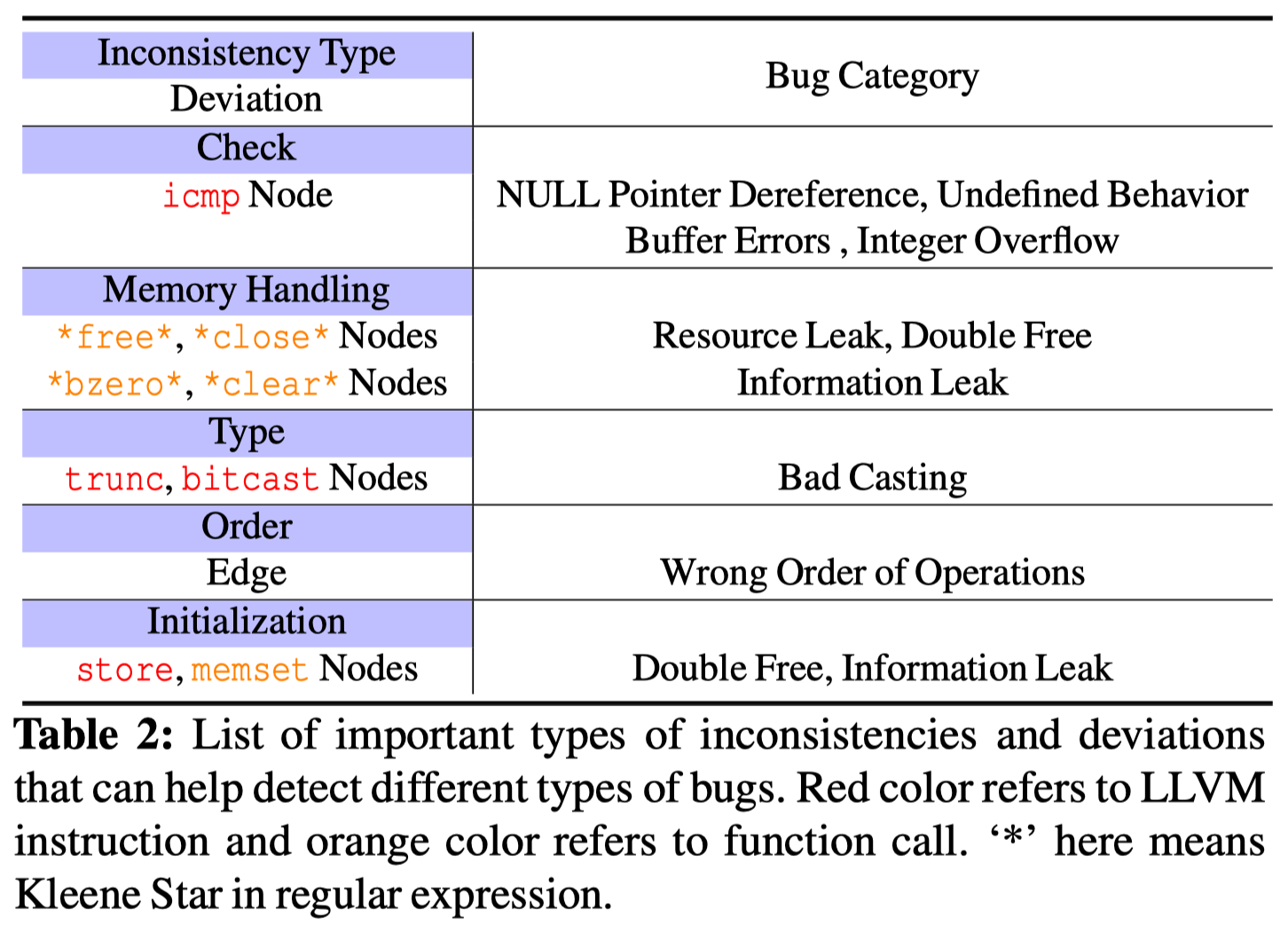
由于通过两步聚类得到的结果并不一定都是漏洞,因此作者建议FICS的使用者使用Deviation Analysis(手动)分析聚类得到的结果,以更快的定位真正的漏洞。大多数漏洞是因为缺少/增加了某些代码片段导致的,作者对缺少/增加的代码片段对应的漏洞类别进行了整理,如下图所示。
Table 2
Evaluation
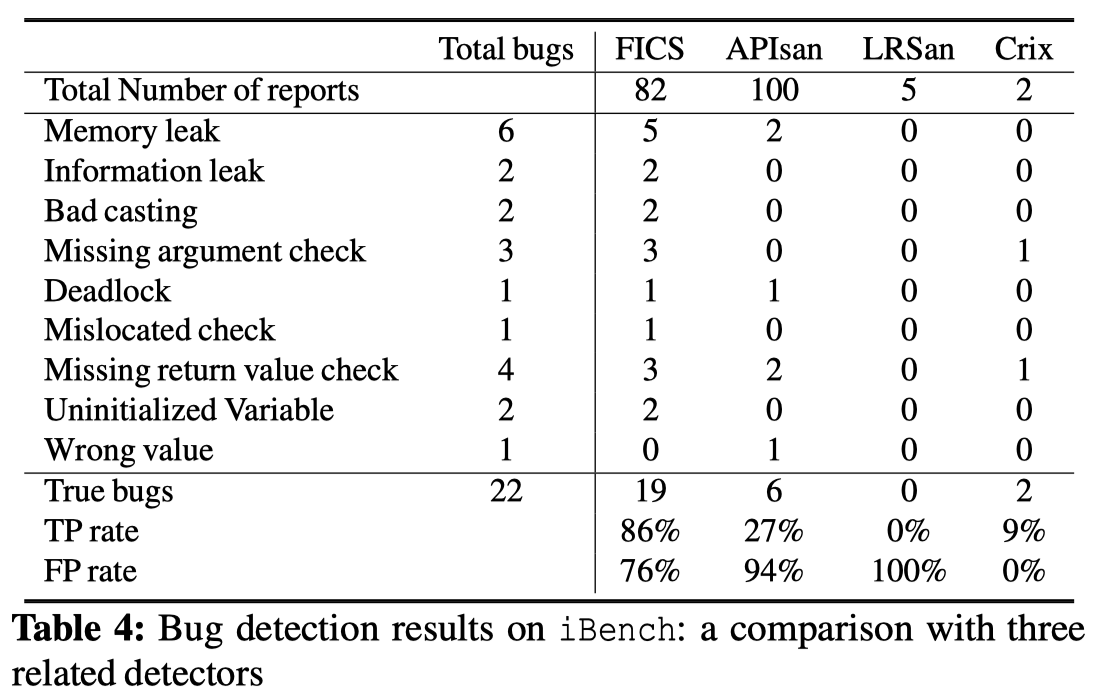
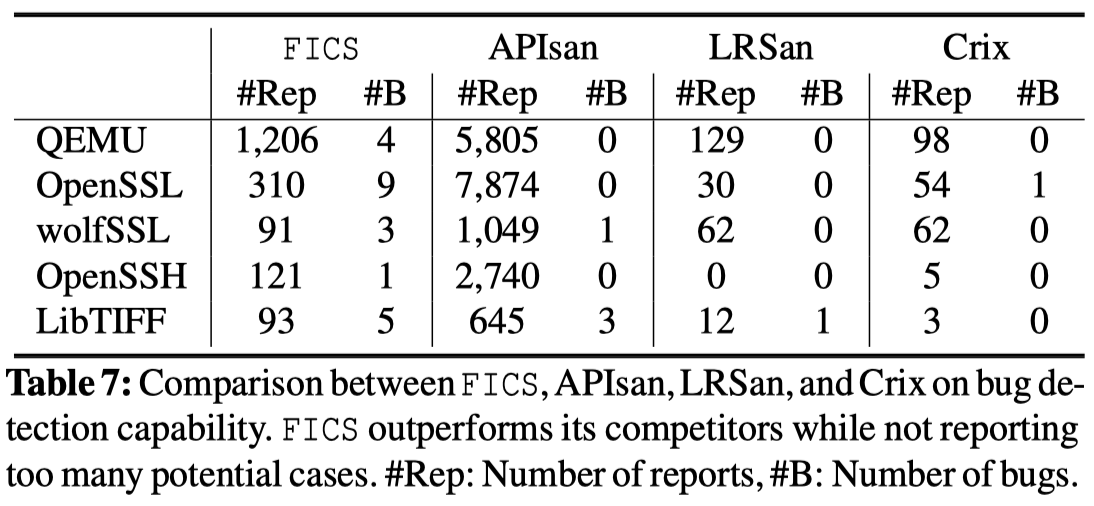
由于之前没有专门用于代码不一致性漏洞检测的数据集,作者设计了一个在五个codebase(several Linux drivers, OpenSSL, libzip, and mbedtls)中含有22个已知漏洞的数据集,并与之前的一些工作进行了对比,如下图所示。
表明了FICS并不只针对特定的某一类/几类漏洞,且比其他工作能够找到更多的漏洞。
Discovered Unknown Bugs
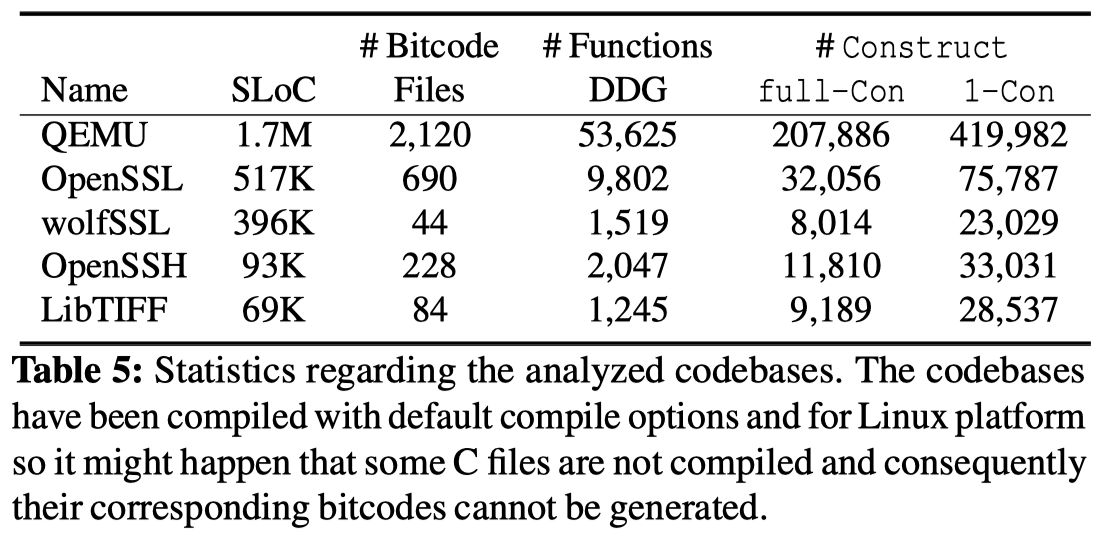
测试集及统计数据:

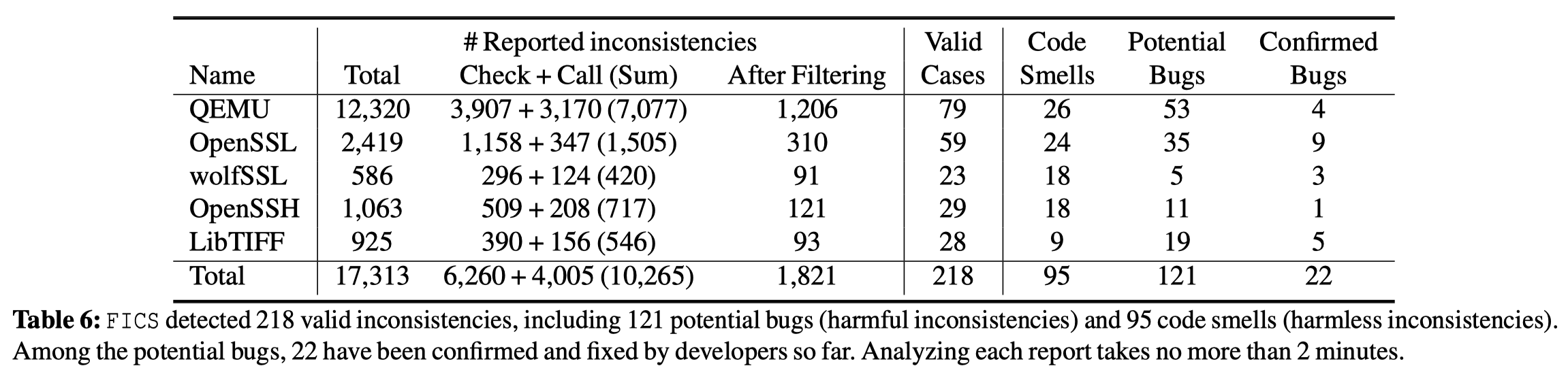
结果:
Case Studies:
Miss Check(70%)、Memory/Information Leak(20%)、Other Bugs(10%)
Performance
20-core workstation with 200 GB of RAM
OPENSSL需要12小时,QEMU 72小时,其他的均在5小时内。
最耗时的为第二步的聚类中的graph embedding generation。
Conclusion
本文中,作者提出了FICS,一种基于ML的通用漏洞检测系统,该系统从待检测的code base中进行学习,不需要额外的训练集。
作者在FICS中提出了一些新的概念和技术,包括Constructs以及两步聚类、两种graph embedding方案。使得FICS具备可扩展性。
作者使用FICS在五个well-tested的开源项目中进行测试,发现了22个未知漏洞。
不一致性分析的方式
- majority voting-based approach
- 聚类,大量误报,将筛选的工作留给人类?